容器的持久化存储
容器的持久化存储是保存容器存储状态的重要手段,存储插件会在容器里挂载一个基于网络或者其他机制的远程数据卷,使得在容器里创建的文件,实际上是保存在远程存储服务器上,或者以分布式的方式保存在多个节点上,而与当前宿主机没有任何绑定关系。这样,无论你在其他哪个宿主机上启动新的容器,都可以请求挂载指定的持久化存储卷,从而访问到数据卷里保存的内容。由于 Kubernetes 本身的松耦合设计,绝大多数存储项目,比如 Ceph、GlusterFS、NFS 等,都可以为 Kubernetes 提供持久化存储能力。
Rook 、ceph简介
Ceph分布式存储系统
Ceph是一种高度可扩展的分布式存储解决方案,提供对象、文件和块存储。在每一个存储节点上,您将找到Ceph存储对象的文件系统和Ceph OSD(对象存储守护程序)进程。在Ceph集群上,您还能够找到Ceph MON(监控)守护程序,它们确保Ceph集群保持高可用性。
Rook
Rook 是一个开源的cloud-native storage编排, 提供平台和框架;为各类存储解决方案提供平台、框架和支持,以便与云原生环境本地集成。
Rook 将存储软件转变为自我管理、自我扩展和自我修复的存储服务,它经过自动化部署、引导、配置、置备、扩展、升级、迁移、灾难恢复、监控和资源管理来实现此目的。
Rook 使用底层云本机容器管理、调度和编排平台提供的工具来实现它自身的功能。
Rook 目前支持Ceph、NFS、Minio Object Store和CockroachDB。
Rook使用Kubernetes原语使Ceph存储系统能够在Kubernetes上运行。下图说明了Ceph Rook如何与Kubernetes集成:
随着Rook在Kubernetes集群中运行,Kubernetes应用程序可以挂载由Rook管理的块设备和文件系统,或者可以使用S3 / Swift API提供对象存储。Rook oprerator自动配置存储组件并监控群集,以确保存储处于可用和健康状态。
Rook oprerator是一个简单的容器,具有引导和监视存储集群所需的全部功能。oprerator将启动并监控ceph monitor pods和OSDs的守护进程,它提供基本的RADOS存储。oprerator通过初始化运行服务所需的pod和其他组件来管理池,对象存储(S3 / Swift)和文件系统的CRD。
oprerator将监视存储后台驻留程序以确保群集正常运行。Ceph mons将在必要时启动或故障转移,并在群集增长或缩小时进行其他调整。oprerator还将监视api服务请求的所需状态更改并应用更改。
Rook oprerator还创建了Rook agent。这些agent是在每个Kubernetes节点上部署的pod。每个agent都配置一个Flexvolume插件,该插件与Kubernetes的volume controller集成在一起。处理节点上所需的所有存储操作,例如附加网络存储设备,安装卷和格式化文件系统。
该rook容器包括所有必需的Ceph守护进程和工具来管理和存储所有数据 - 数据路径没有变化。 rook并没有试图与Ceph保持完全的忠诚度。 许多Ceph概念(如placement groups和crush maps)都是隐藏的,因此您无需担心它们。 相反,Rook为管理员创建了一个简化的用户体验,包括物理资源,池,卷,文件系统和buckets。 同时,可以在需要时使用Ceph工具应用高级配置。
Rook在golang中实现。Ceph在C ++中实现,其中数据路径被高度优化。
前期准备
1.已有一个能够正常跑应用的k8s集群
2.在集群中至少有三个节点可用,满足ceph高可用要求,而且每个服务器具有一块未格式化未分区的硬盘。
我这边使用的环境是VMware workstation,一个msater俩worker,每个主机各新增一个100G的磁盘。(已配置master节点使其支持运行pod。)
不重启系统,重新扫描scsi总线查看到新添加的磁盘。详看文章:https://www.cnblogs.com/sanduzxcvbnm/p/14841818.html
3.rook-ceph项目地址:https://github.com/rook/rookbash
部署文档: https://github.com/rook/rook/blob/master/Documentation/ceph-quickstart.md
4.rook使用存储方式
rook默认使用全部节点的全部资源,rook operator自动在全部节点上启动OSD设备,Rook会用以下标准监控并发现可用设备:
设备没有分区
设备没有格式化的文件系统
Rook不会使用不知足以上标准的设备。另外也能够经过修改配置文件,指定哪些节点或者设备会被使用。
5.无另外说明,以下全部操作都在master节点执行。
添加新磁盘
在所有节点添加1块100GB的新磁盘:/dev/sdc,作为OSD盘,提供存储空间,添加完成后扫描磁盘,确保主机能够正常识别到: (新添加的磁盘不用挂载配置到/etc/fstab上)
#扫描 SCSI总线并添加 SCSI 设备
for host in $(ls /sys/class/scsi_host) ; do echo "- - -" > /sys/class/scsi_host/$host/scan; done
#重新扫描 SCSI 总线
for scsi_device in $(ls /sys/class/scsi_device/); do echo 1 > /sys/class/scsi_device/$scsi_device/device/rescan; done
#查看已添加的磁盘,能够看到sdb说明添加成功
lsblk
本次搭建的基本原理图:
事先准备好使用的镜像
须要用到的镜像,部署服务前首先得将镜像导入
rook/ceph:v1.6.3
ceph/ceph:v15.2.11
quay.io/cephcsi/cephcsi:v3.1.1.4
# 如下这些镜像会从k8s.gcr.io中拉取,网络的问题拉取不到,这里采用从其他地方拉取,然后重新tag的方法
k8s.gcr.io/sig-storage/csi-snapshotter:v4.0.0
docker pull antmoveh/csi-snapshotter:v4.0.0
docker tag antmoveh/csi-snapshotter:v4.0.0 k8s.gcr.io/sig-storage/csi-snapshotter:v4.0.0
k8s.gcr.io/sig-storage/csi-provisioner:v2.0.4
docker pull antmoveh/csi-provisioner:v2.0.4
docker tag antmoveh/csi-provisioner:v2.0.4 k8s.gcr.io/sig-storage/csi-provisioner:v2.0.4
k8s.gcr.io/sig-storage/csi-resizer:v1.0.1
docker pull antmoveh/csi-resizer:v1.0.1
docker tag antmoveh/csi-resizer:v1.0.1 k8s.gcr.io/sig-storage/csi-resizer:v1.0.1
k8s.gcr.io/sig-storage/csi-attacher:v3.0.2
docker pull antmoveh/csi-attacher:v3.0.2
docker tag antmoveh/csi-attacher:v3.0.2 k8s.gcr.io/sig-storage/csi-attacher:v3.0.2
k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.0.1
docker pull antmoveh/csi-node-driver-registrar:v2.0.1
docker tag antmoveh/csi-node-driver-registrar:v2.0.1 k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.0.1
部署Rook Operator
安装
# 克隆指定版本
git clone --single-branch --branch v1.6.3 https://github.com/rook/rook.git
# 进入到目录
cd rook/cluster/examples/kubernetes/ceph
#全部的pod都会在rook-ceph命名空间下建立
kubectl create -f common.yaml
# k8s1.15版本及其以上的需要这个
kubectl create -f crds.yaml
#部署Rook操做员
kubectl create -f operator.yaml
# 在继续操作之前,验证 rook-ceph-operator 是否处于“Running”状态:
kubectl get pod -n rook-ceph
创建 Rook Ceph 集群
kubectl create -f cluster.yaml
# 通过 kubectl 来查看 rook-ceph 命名空间下面的 Pod 状态
kubectl get pods -n rook-ceph
# OSD Pod 的数量将取决于集群中的节点数量以及配置的设备和目录的数量
# 如果要删除已创建的Ceph集群,可执行命令:kubectl delete -f cluster.yaml
Rook 工具箱---Ceph toolbox 命令行工具
# 验证集群是否处于正常状态,可以使用 Rook 工具箱,Rook 工具箱是一个用于调试和测试 Rook 的常用工具容器,该工具基于 CentOS 镜像,所以可以使用 yum 来轻松安装更多的工具包。
# 默认启动的Ceph集群,是开启Ceph认证的,这样你登录Ceph组件所在的Pod里,是无法去获取集群状态,以及执行CLI命令,这时须要部署Ceph toolbox,命令如下
kubectl create -f toolbox.yaml
# 一旦 toolbox 的 Pod 运行成功后,就可以使用下面的命令进入到工具箱内部进行操作:
# 进入ceph tool容器
kubectl exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') -n rook-ceph -- bash
#查看ceph状态
# ceph status
cluster:
id: b0228f2b-d0f4-4a6e-9c4f-9d826401fac2
health: HEALTH_WARN
mons are allowing insecure global_id reclaim
services:
mon: 3 daemons, quorum a,b,c (age 90m)
mgr: a(active, since 87m)
mds: myfs:1 {0=myfs-b=up:active} 1 up:standby-replay
osd: 3 osds: 3 up (since 88m), 3 in (since 5h)
data:
pools: 4 pools, 97 pgs
objects: 22 objects, 2.2 KiB
usage: 3.2 GiB used, 297 GiB / 300 GiB avail
pgs: 97 active+clean
io:
client: 852 B/s rd, 1 op/s rd, 0 op/s wr
#查看osd状态
# ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 develop-worker-2 1089M 98.9G 0 0 0 0 exists,up
1 develop-worker-1 1089M 98.9G 0 0 1 105 exists,up
2 develop-master-1 1089M 98.9G 0 0 0 0 exists,up
# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 300 GiB 297 GiB 195 MiB 3.2 GiB 1.06
TOTAL 300 GiB 297 GiB 195 MiB 3.2 GiB 1.06
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 94 GiB
replicapool 2 32 0 B 0 0 B 0 94 GiB
myfs-metadata 3 32 2.2 KiB 22 1.5 MiB 0 94 GiB
myfs-data0 4 32 0 B 0 0 B 0 94 GiB
# rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
device_health_metrics 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
myfs-data0 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
myfs-metadata 1.5 MiB 22 0 66 0 0 0 2496 1.2 MiB 45 13 KiB 0 B 0 B
replicapool 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
total_objects 22
total_used 3.2 GiB
total_avail 297 GiB
total_space 300 GiB
#至此已经部署完成了,查看rook-ceph命名空间下的pod,首先看pod的状况,有operator、mgr、agent、discover、mon、osd、tools,且osd-prepare是completed的状态,其它是running的状态
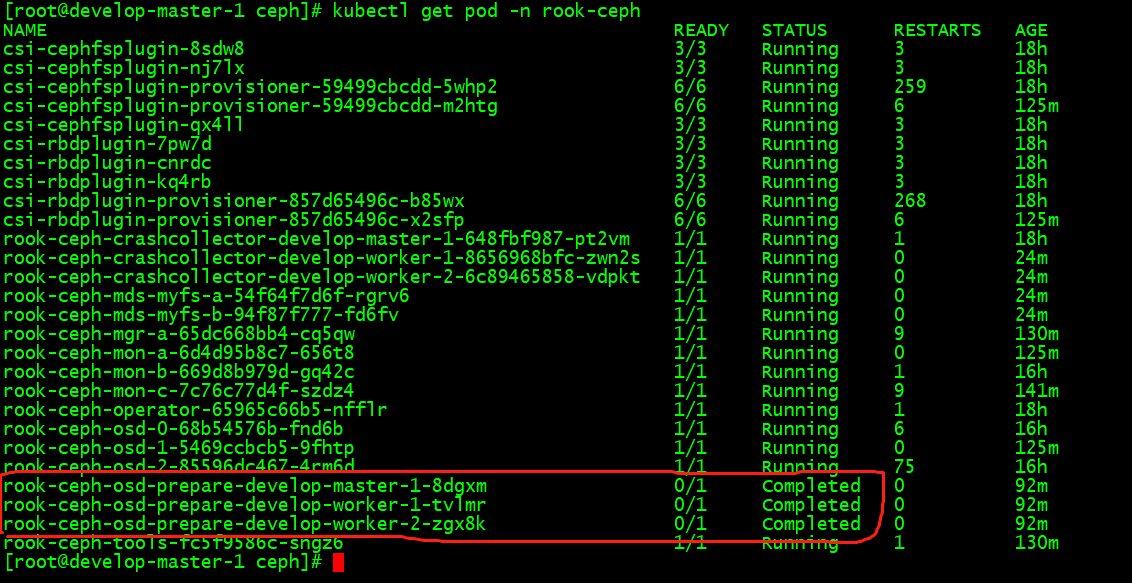
比如现在我们要查看集群的状态,需要满足下面的条件才认为是健康的:
所有 mons 应该达到法定数量
mgr 应该是激活状态
至少有一个 OSD 处于激活状态
如果不是 HEALTH_OK 状态,则应该查看告警或者错误信息
Ceph Dashboard
Ceph 有一个 Dashboard 工具,可以在上面查看集群的状态,包括总体运行状态,mgr、osd 和其他 Ceph 进程的状态,查看池和 PG 状态,以及显示守护进程的日志等等。
可以在上面的 cluster CRD 对象中开启 dashboard,设置 dashboard.enable=true即可,这样 Rook Operator 就会启用 ceph-mgr dashboard 模块,(默认这个是开启的)并将创建一个 Kubernetes Service 来暴露该服务,将启用端口 8443进行 https 访问,如果 Ceph 集群部署成功了,可以使用下面的命令来查看 Dashboard 的 Service:kubectl get service -n rook-ceph
这里的 rook-ceph-mgr 服务用于报告 Prometheus metrics 指标数据的,而后面的的 rook-ceph-mgr-dashboard 服务就是我们的 Dashboard 服务,如果在集群内部我们可以通过 DNS 名称 http://rook-ceph-mgr-dashboard.rook-ceph:8443或者 CluterIP http://10.3.255.193:8443来进行访问,但是如果要在集群外部进行访问的话,我们就需要通过 Ingress 或者 NodePort 类型的 Service 来暴露了。
有如下两种方式
# 暴露方式有多种选择适合本身的一个便可
https://github.com/rook/rook/blob/master/Documentation/ceph-dashboard.md
第一种方式是修改rook-ceph-mgr-dashboard,原先是cluster ip,修改成nodeport形式就可以访问了。
#执行完cluster.yaml后rook会自动帮咱们建立ceph的Dashboard,pod及service以下图,默认dashboard为ClusterIP,须要咱们改成NodePort对外暴露服务。
kubectl edit svc rook-ceph-mgr-dashboard -n rook-ceph
在访问的时候需要登录才能够访问,Rook 创建了一个默认的用户 admin,并在运行 Rook 的命名空间中生成了一个名为 rook-ceph-dashboard-admin-password 的 Secret,要获取密码,可以运行以下命令:
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
访问地址,注意是https,http会访问不成功
用上面获得的密码和用户名 admin 就可以登录 Dashboard 了,在 Dashboard 上面可以查看到整个集群的状态
注意:使用后面的那个端口号,这个是节点端口
https://nodeip:32111
第二种方式
执行如下这个,根据实际情况修改,默认的8443端口已被占用
kubectl create -f dashboard-external-https.yaml
创建完成后我们可以查看到新创建的 rook-ceph-mgr-dashboard-external 这个 Service 服务:
https://nodeip:32009
访问Web Ceph Dashboard
Ceph Dashboard首页,点击admin修改登录密码
配置 Dashboard
除此之外在使用上面的 CRD 创建 ceph 集群的时候我们还可以通过如下的配置来配置 Dashboard:
spec:
dashboard:
urlPrefix: /ceph-dashboard
port: 8443
ssl: true
urlPrefix:如果通过反向代理访问 Dashboard,则可能希望在 URL 前缀下来访问,要让 Dashboard 使用包含前缀的的链接,可以设置 urlPrefix
port:可以使用端口设置将为 Dashboard 提供服务的端口从默认值修改为其他端口,K8S 服务暴露的端口也会相应的更新
ssl:通过设置 ssl=false,可以在不使用 SSL 的情况下为 Dashboard 提供服务
监控
每个 Rook 群集都有一些内置的指标 collectors/exporters,用于使用 Prometheus 进行监控。
存储
对于 Rook 暴露的三种存储类型可以查看对应的文档:
块存储(https://rook.io/docs/rook/v1.1/ceph-block.html):创建一个 Pod 使用的块存储
对象存储(https://rook.io/docs/rook/v1.1/ceph-object.html):创建一个在 Kubernetes 集群内部和外部都可以访问的对象存储
共享文件系统(https://rook.io/docs/rook/v1.1/ceph-filesystem.html):创建要在多个 Pod 之间共享的文件系统
ceph分布式存储使用
RBD
1.安装rbd插件storageclass
# kubectl apply -f rook/cluster/examples/kubernetes/ceph/csi/rbd/storageclass.yaml
2.查看建立rbd结果
# kubectl get storageclasses.storage.k8s.io
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 11s
3.建立pvc指定storageClassName为rook-ceph-block框

CEPHFS安装使用
1.安装cephfs元数据存储池及插件storageclass
kubectl apply -f rook/cluster/examples/kubernetes/ceph/filesystem.yaml
kubectl apply -f rook/cluster/examples/kubernetes/ceph/csi/cephfs/storageclass.yaml
2.以pod的形式部署在rook-ceph命名空间中,会有两个pod。
kubectl -n rook-ceph get pod -l app=rook-ceph-mds
NAME READY STATUS RESTARTS AGE
rook-ceph-mds-myfs-a-54f64f7d6f-rgrv6 1/1 Running 0 19s
rook-ceph-mds-myfs-b-94f87f777-fd6fv 1/1 Running 0 17s
3.查看建立rbd结果
kubectl get storageclasses.storage.k8s.io
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 12m
rook-cephfs rook-ceph.cephfs.csi.ceph.com Delete Immediate true 57s
4.cephfs使用和rbd同样指定storageClassName的值便可,须要注意的是rbd只支持ReadWriteOnce,cephfs能够支持ReadWriteMany。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
namespace: default
name: airflow-service-log-pvc
spec:
accessModes:
#- ReadWriteOnce
- ReadWriteMany
resources:
requests:
storage: 2Gi
storageClassName: rook-cephfs
测试
安装一个MySQL,使用storageClassName: rook-cephfs,可以查看到这个这次扩容
还能安装CSI插件给PVC创建快照
故障修复
1.rook-ceph-crashcollector-k8s-master3-offline-217-d9ff847442ng7p 一直处于init状态,输入命令查看pod启动状态 kubectl describe pod rook-ceph-crashcollector-k8s-master3-offline-217-d9ff847442ng7p -n rook-ceph报错信息如下:
MountVolume.SetUp failed for volume "rook-ceph-crash-collector-keyring" : secret "rook-ceph-crash-collector-keyring" not foun
修复过程:
删除集群
kubectl delete -f cluster.yaml
之后会一直卡在删除的阶段。
kubectl edit customresourcedefinitions.apiextensions.k8s.io cephclusters.ceph.rook.io
删除文件中状态两行
每个节点都需要执行
rm -rf /var/lib/rook/*
rm -rf /var/lib/kubelet/plugins/rook-ceph.*
rm -rf /var/lib/kubelet/plugins_registry/rook-ceph.*
重新安装,再次查看
kubectl create -f common.yaml
kubectl create -f operator.yaml
kubectl create -f cluster.yaml
2.现象:rook-ceph部分容器为一直创建的状态
排查过程:查看pod状态后发现缺少rook-ceph-csi-config文件,github相关资料https://github.com/rook/rook/issues/6162。大概原因是由于服务器重启或者是服务器发生抖动,导致pod飘逸重建。重建失败
解决方法:
kubectl delete -f rook/cluster/examples/kubernetes/ceph/operator.yaml
kubectl apply -f rook/cluster/examples/kubernetes/ceph/common.yaml
kubectl apply -f rook/cluster/examples/kubernetes/ceph/operator.yaml
3.清理ceph集群
每个节点都需要执行
rm -rf /var/lib/rook/*
rm -rf /var/lib/kubelet/plugins/rook-ceph.*
rm -rf /var/lib/kubelet/plugins_registry/rook-ceph.*
https://rook.io/docs/rook/v1.4/ceph-teardown.html
ceph 历史报错回收
使用ceph -s查看集群状态,发现一直有如下报错,且数量一直在增加.经查当前系统运行状态正常,判断这里显示的应该是历史故障,处理方式如下:
查看历史crash
ceph crash ls-new
根据ls出来的id查看详细信息
ceph crash info <crash-id>
将历史crash信息进行归档,即不再显示
ceph crash archive <crash-id>
归档所有信息
ceph crash archive-all
ceph基础运维命令
进入rook-ceph命令行工具pod
kubectl exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') -n rook-ceph -- bash
检查Ceph集群状态
ceph -s
如果需要实时观察Ceph集群状态变化,可使用如下命令
ceph -w
检查集群容量使用情况
ceph df
查看集群OSD配置
ceph osd df
查看OSD在集群布局中的设计分布
ceph osd tree
列式pool列表
ceph osd lspools
rook-ceph开启S3 API接口
创建过程:
cd /opt/k8s-install/rook/cluster/examples/kubernetes/ceph
创建对象存储,Rook操作员将创建启动服务所需的所有池和其他资源。这可能需要三四分钟才能完成
kubectl create -f object.yaml
kubectl -n rook-ceph get pod -l app=rook-ceph-rgw
创建存储桶,客户端可以在其中读取和写入对象。可以通过定义存储类来创建存储桶,类似于块存储和文件存储所使用的模式。首先,定义允许对象客户端创建存储桶的存储类。存储类定义对象存储系统,存储桶保留策略以及管理员所需的其他属性
kubectl create -f storageclass-bucket-delete.yaml
创建申请声明。基于此存储类,对象客户端现在可以通过创建对象存储桶声明(OBC)来请求存储桶。创建OBC后,Rook-Ceph存储桶配置程序将创建一个新存储桶。请注意,OBC引用了上面创建的存储类。
kubectl create -f object-bucket-claim-delete.yaml
创建集群外部访问
Rook设置了对象存储,因此Pod可以访问群集内部。如果您的应用程序在集群外部运行,则需要通过来设置外部服务NodePort。
首先,请注意将RGW公开到群集内部的服务。我们将保留该服务不变,并为外部访问创建一个新服务。
创建之前修改rgw-external.yaml,配置一个固定的nodeport端口例如38000
kubectl create -f rgw-external.yaml
创建一个用户
如果您需要创建一组独立的用户凭据来访问S3端点,请创建一个CephObjectStoreUser。该用户将使用S3 API连接到集群中的RGW服务。用户将独立于您可能在本文档前面的说明中创建的任何对象存储桶声明。
kubectl create -f object-user.yaml
获取用户的AccessKey和SecretKey
这里建议先print 打印出来,之后再echo "xxxx" | base64 --decode
kubectl -n rook-ceph get secret rook-ceph-object-user-my-store-my-user -o yaml | grep AccessKey | awk '{print $2}' | base64 --decode
kubectl -n rook-ceph get secret rook-ceph-object-user-my-store-my-user -o yaml | grep SecretKey | awk '{print $2}' | base64 --decode
最终提供访问的地址及认证信息
例如:
access_key = 'BMXG3WP8JA9D1GSD2AJJ'
secret_key = 'vl32x2t0sBxy0BEgcY9Iz442HK2HobPTNw4T99yK'
host = '192.168.10.237:38000'
rook-ceph1.4.1 升级到1.4.8
只需要导入两个镜像,之后重新apply operator.yaml即可,rook会自动检查并升级重启
docker load -i cephcsi.tar
docker load -i rook-ceph.tar
kubectl apply -f operator.yaml
问题
1.进入ceph tool容器后查看ceph状态,会发现状态是HEALTH_WARN,下面有一行提示:mons are allowing insecure global_id reclaim
解决办法:禁用不安全模式
进入ceph tool容器后执行如下命令:
ceph config set mon auth_allow_insecure_global_id_reclaim false
稍后再次查看,ceph status就变成HEALTH_OK了
额外知识点
pv的三种访问模式
ReadWriteOnce,RWO,仅可被单个节点读写挂载
ReadOnlyMany,ROX,可被多节点同时只读挂载
ReadWriteMany,RWX,可被多节点同时读写挂载
pv回收策略
Retain,保持不动,由管理员手动回收
Recycle,空间回收,删除全部文件,仅NFS和hostPath支持
Delete,删除存储卷,仅部分云端存储支持

![PIP升级+安装Django命令[WARNING: Retrying (Retry(total=4, connect=None...]](https://www.kunjuke.com/file/css/thumb/4.jpg/280-180.jpg)



